2019-06-25, 10:15–10:45, Room 1
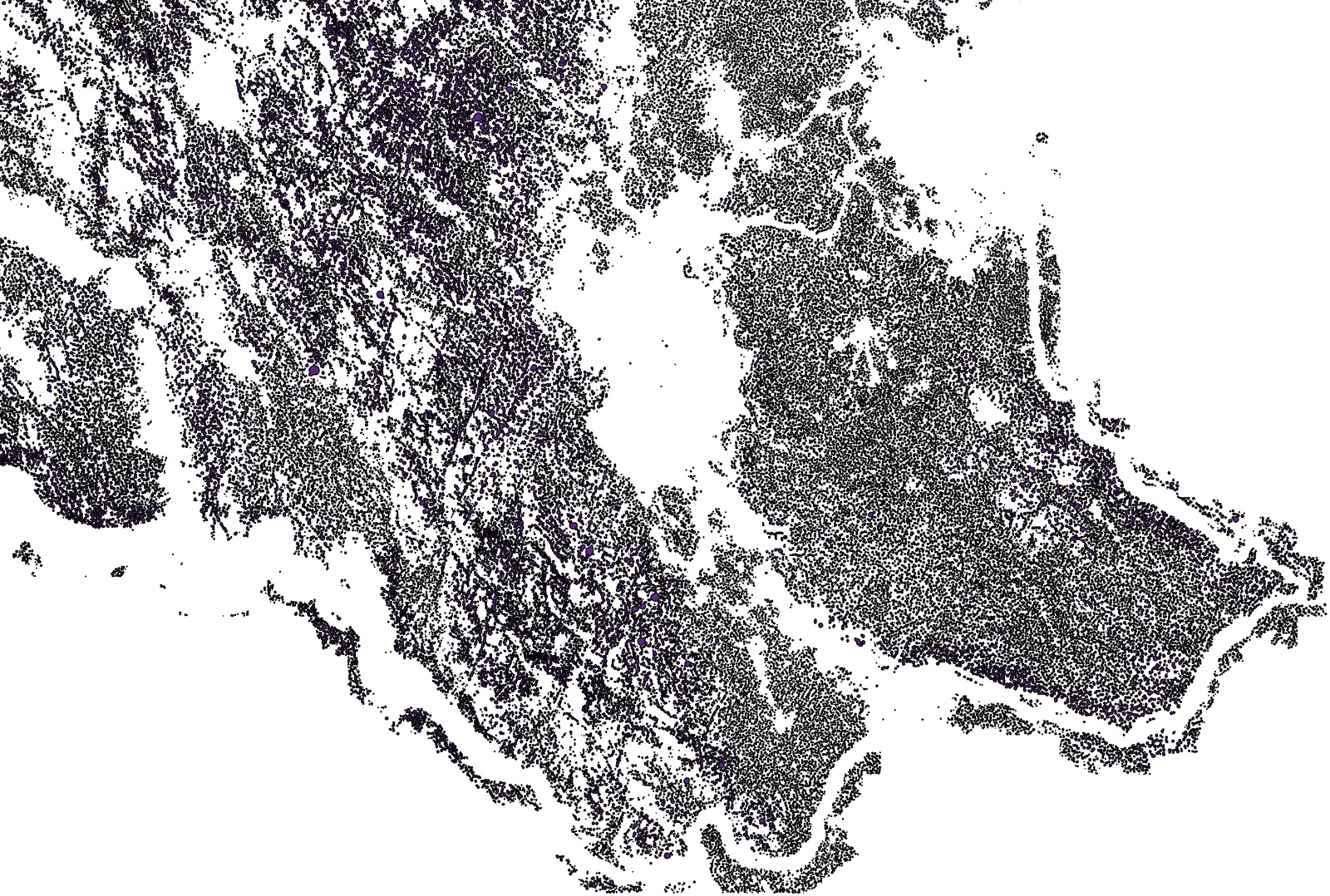
Aerial lidar scan of Slovenia with resolution 1 m^2 was used to segment out a large number of dolines, specific relief depressions that are a diagnostic feature of karst landscape with typical diameter of 42 m. This talk will cover data processing, label bootstrapping, TPU based model training and inference that was done to deliver a catalog of 472k segmented objects.
Project goal was to create catalog of dolines based on publicly available lidar scan of Slovenia (20k km^2 at 1 m^2 resolution).
We estimated that there would be between 200k and 1M dolines on the state territory. Assuming 10 seconds of work to label each object it would take between 23 and 115 human days to label the entire territory, so manual labor was not feasible and we attempted machine learning approach.
We used manually created approximate segmentation dataset, produced with about 8 hours of manual work to train an image segmentation algorithm. We used the trained model to segment previously unseen data and manually reviewed segmentations that it produced. We joined original manual labels with reviewed segmentations and trained the segmentation algorithm again on the union. We repeated this process until we produced a diverse enough label dataset which we used to train the final segmentation model. This model we finally use to create a catalogue of all Slovenian dolines.
The segmentation algorithm used was U-nets. Significant data augmentation was applied to extend the dataset. Finally, the labelled country-wide dataset was manually reviewed by a domain expert.
During this project we also developed and open sourced a Python library for semi-supervised label creation.
{kind=link}
{kind=link}
{kind=link}